

My Augmented Memory
Every AI tool I use forgets me, so I built a memory system that I can share across all tools and agents: three layers and four mechanisms. Work in progress but worth sharing.

I use AI tools and agents on a daily basis: Perplexity for deep research; OpenClaw as a personal assistant and fitness trainer; Claude Opus for complex projects; n8n for automation; RooCode and Claude Code for building stuff. But none of them remembers anything useful about me. Every tool maintains its own closed memory silo. I don’t control what gets stored, can’t edit it, and can’t share it across all my tools. Even within a single platform, memory is shallow: fact-based at best, with no concept of how I work, what matters now, or what I’ve learned over time.
Many years ago, while working on Eternime, I thought about an augmented memory system that would capture everything about me: who I am, what I know, how I do things, and what happens to me. At the time, I had no idea how to build it. This was years before the LLM revolution.
This year, at last, I have the tools and the incentive to build it. Starting from OpenClaw’s memory approach, I designed a unified memory architecture that would work across all my tools. It’s still in the early days, but I wanted to share it with you.
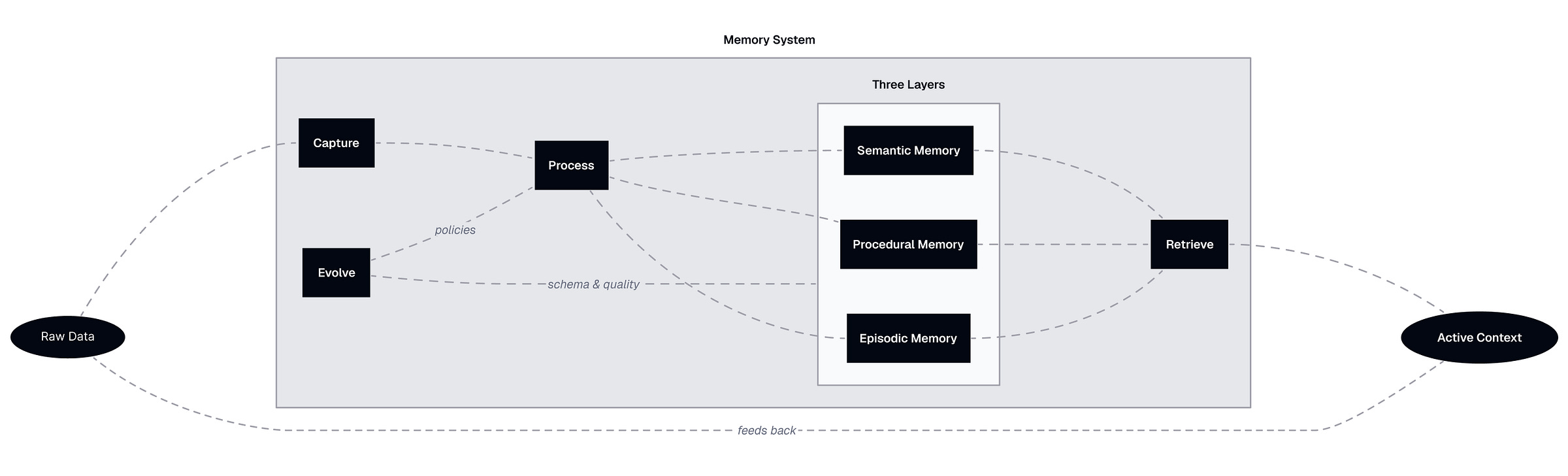
The Augmented Memory system has three layers of memory, four mechanisms that sustain it, and seven artifacts that make it concrete.
Layers solve the “what to remember” problem. Semantic memory is a knowledge graph of my world: people, projects, tools, facts, relationships, and identity. Procedural memory captures how I like things done: capabilities, workflows, templates, tools, preferences, stored as editable Markdown files. Episodic memory stores structured events (not raw logs) with temporal summaries at daily, weekly, monthly, quarterly, and yearly scales.
Mechanisms solve the “how to keep it alive” problem. Capture ingests raw data from multiple sources. Process consolidates it overnight into structured memories across all three layers (like the brain during sleep). Retrieve assembles an active context for a specific task by pulling from all layers. Evolve improves the system itself: schema changes, decay policies, conflict resolution, and forgetting.
Artifacts make it usable. A knowledge graph, domain views, working memory views, expertise files, templates, atomic events, and temporal summaries. Raw data sits outside as input. Active context sits outside as output. The memory system is what happens in between.
Memory Layers
Each layer stores a different kind of knowledge, evolves at a different pace, and serves a different purpose during retrieval.
1. Semantic Memory: What I Know About My World
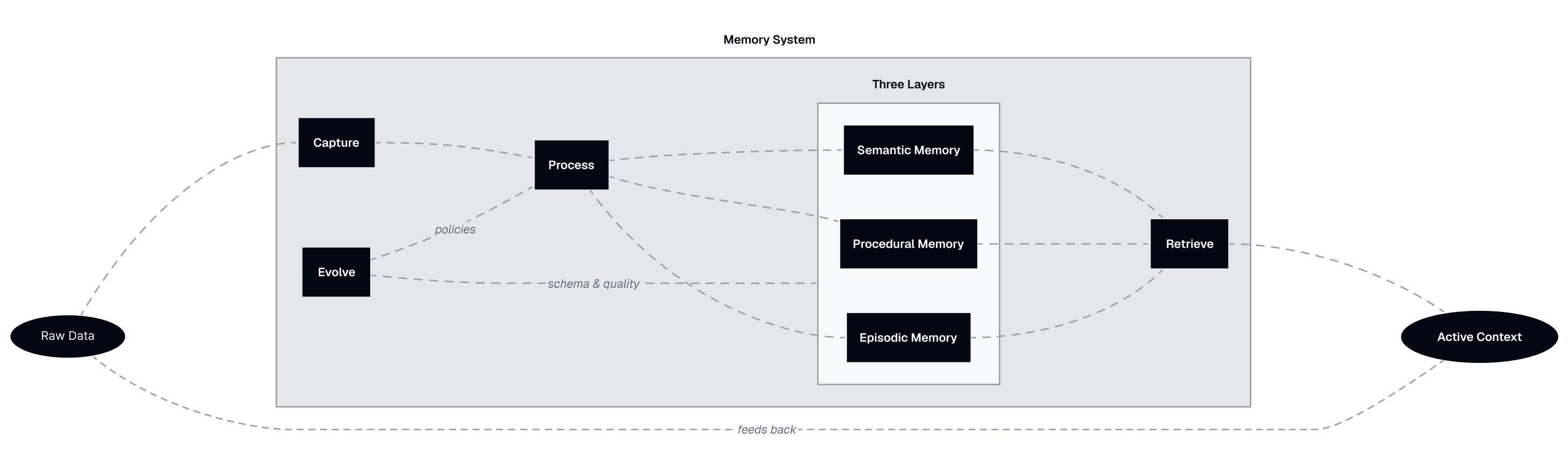
This is the knowledge graph. Entities (people, organizations, projects, tools, concepts) connected by relationships, with facts stored as properties on both nodes and edges. “Marius” is a Person node. “Newsletter” is a Project node. The relationship between them is “works-on.” The fact that the newsletter is weekly is a property of the Newsletter node. The fact that I prefer blunt communication is a property of my node.
My identity lives here too. My values, principles, and the things that define who I am. They’re not a separate layer. They’re semantic nodes with near-zero decay rate and high retrieval priority. “I value honesty” is a fact about me, stored the same way as “Newsletter is weekly,” but flagged as permanent.
I organize all entities and relationships under seven life domains: Work, Wealth, Health, Relationships, Growth, Fun, and Environment, and ~43 subtopics (e.g., Health/Fitness or Fun/Guitar). This taxonomy is stored in the graph too, and it’s editable. If I pick up a new domain of interest, the taxonomy grows. A view is generated for each topic, pulling together all relevant entities, facts, events, and procedural files. This gives me a human-readable perspective on each area of my life and helps agents retrieve focused context.
Semantic memory is the most stable layer. Facts change, relationships evolve, but the structure persists and grows. It evolves primarily by extracting patterns from episodic memory. After multiple events related to a project, the system can infer that “Newsletter is a weekly project” and add this to the graph. It also evolves through my direct curation, when I notice something wrong and fix it.
2. Procedural Memory: How I Like Things Done
This is where the real productivity gains are, and it’s the most neglected dimension in every AI memory system I’ve seen. Procedural memory captures how I do things: my standard operating procedures, templates, workflows, tool configurations, and behavioral preferences. I store these as human-readable Markdown files with front-matter metadata. This maps well onto the structure Claude uses for its own skills and plugins, which is becoming a de facto standard. The taxonomy:
Tools: what I use. Gmail, OpenClaw, n8n, Perplexity API, custom scripts. A directory of what’s available and how to connect to it, not how to use it.
Skills: how to do specific things well. newsletter-research captures how I research before writing (Tavily for the wide net, Perplexity Sonar for deep dives). financial-statement-design describes exactly how I format P&L statements.
Templates: reusable output structures. My newsletter-brief template evolves as I refine my process, but the underlying research capability stays stable.
Workflows: step-by-step processes combining multiple capabilities and tools. publish-newsletter chains research, proofreading, image generation, and distribution.
Capabilities: higher-level bundles of everything above. The saas-sales capability includes go-to-market workflows, people-research capabilities, cold-email templates, and domain-specific preferences.
General preferences: the AGENTS.md file. “Be blunt,” “When in doubt, ask.” “One question at a time.” These apply everywhere.
Each file links to relevant entities in the semantic graph via front-matter metadata, enabling the system to maintain connections between how I do things and what I know.
A special place here goes to the memory-management capability: the set of workflows, templates, capabilities, and tools that define how the memory system itself operates. The policies for updating, retrieving, conflict resolution, and default taxonomies. The system’s own operating manual is stored as procedural memory. Yes, structural-memory-evolution is a skill inside this capability. It’s turtles all the way down.
This is where most of my manual work happens. Claude’s built-in skill writer turns simple tasks into complicated procedures, so I gave mine a simpler template and made it obsess over Occam’s razor. But I still end up editing these files by hand. I write three to five new capabilities each week for repetitive tasks, and the backlog of things still in my head is long.
3. Episodic Memory: What Has Happened to Me
These are atomic events: a client call, a work session, a doctor’s appointment, a workout, dinner with my mom. There are several events in a day, usually lasting between 15 minutes and a few hours. They’re not raw data. They’re processed, extracted, and linked to semantic memory:
Timestamp and duration
Entities involved (linked to the graph)
Domain and topic
Summary of what happened
Outcomes and decisions
Source metadata
Detailed contents
I store them in memory/episodic/daily/YYYY/MM/DD/ as Markdown files with YAML front matter. Retrieval is hard this way. I plan to move them into a vector store.
One thing I discovered is that it’s a great idea to build temporal summaries at multiple scales: daily, weekly, monthly, quarterly, yearly. These summarize the important things from a given timeframe. They catch patterns invisible at the granular level (“gained 3 kg over Q1”). When looking into the past, they work like human memory: we remember the important things and forget the details.
This is the most dynamic layer. It grows daily, and it’s the primary source for semantic memory (and to a lesser extent, procedural). It’s also the least exploited part of my system. Right now, it only processes my agentic sessions emails and calendar events. But there’s much more to capture: geolocation, health data, voice memos, and photos.
Artifacts
Seven types of artifacts (I know it’s not an accurate name from an architectural perspective, but bear with me). Six of them are inside the memory system and one outside:
The knowledge graph: entities, relationships, facts, metadata. Stored in a JSONL file for now, later moving to a proper graph database.
Domain views: pre-assembled Markdown files that pull together relevant entities, facts, events, and procedural files for each of my 7 domains and 43 topics. The “Health/Medical” view includes my medical history, genetic predispositions, blood test results, and medications. Some views update monthly (Health/Medical), others weekly (Health/Fitness), and others daily (Work/DE Labs). These solve two problems: they make the graph human-readable so I can review and edit it, and they give agents a pre-assembled context package rather than querying the entire graph.
Working memory views: a special category. These surface the most important and urgent context for different time horizons, across all domains. The “Today” view has today’s calendar, active projects, and urgent tasks. “This Week” is broader. They regenerate on schedule.
Expertise: all procedural memory items except templates.
Templates: separate because they’re often stored externally (Google Docs) and evolve faster than the capabilities they support.
Atomic events: the episodic memory items described above.
Temporal summaries: compressions of events at different time scales, with references to source events.
Outside the memory system: raw data. Agent sessions, emails, documents, messages, health data, voice memos, calendar meetings, and blood tests. This is input, not memory. It gets processed into the layers above.
The output of memory retrieval is an active context: a structured bundle of information assembled for a specific task. Active context is ephemeral. It exists for the duration of a session, then its outcomes become new raw data that feeds back into capture.
The Mechanisms
The memory is a living system. Without these mechanisms working properly, it’s just a pile of files.
1. Capturing
Ingesting raw data from multiple sources and storing it before processing. My OpenClaw session logs, documents I create, Apple Health exports, calendar events, and emails.
It’s a continuous process that runs whenever new data is available. It’s also tedious to set up, because raw data is scattered across platforms, formats, and APIs.
2. Processing
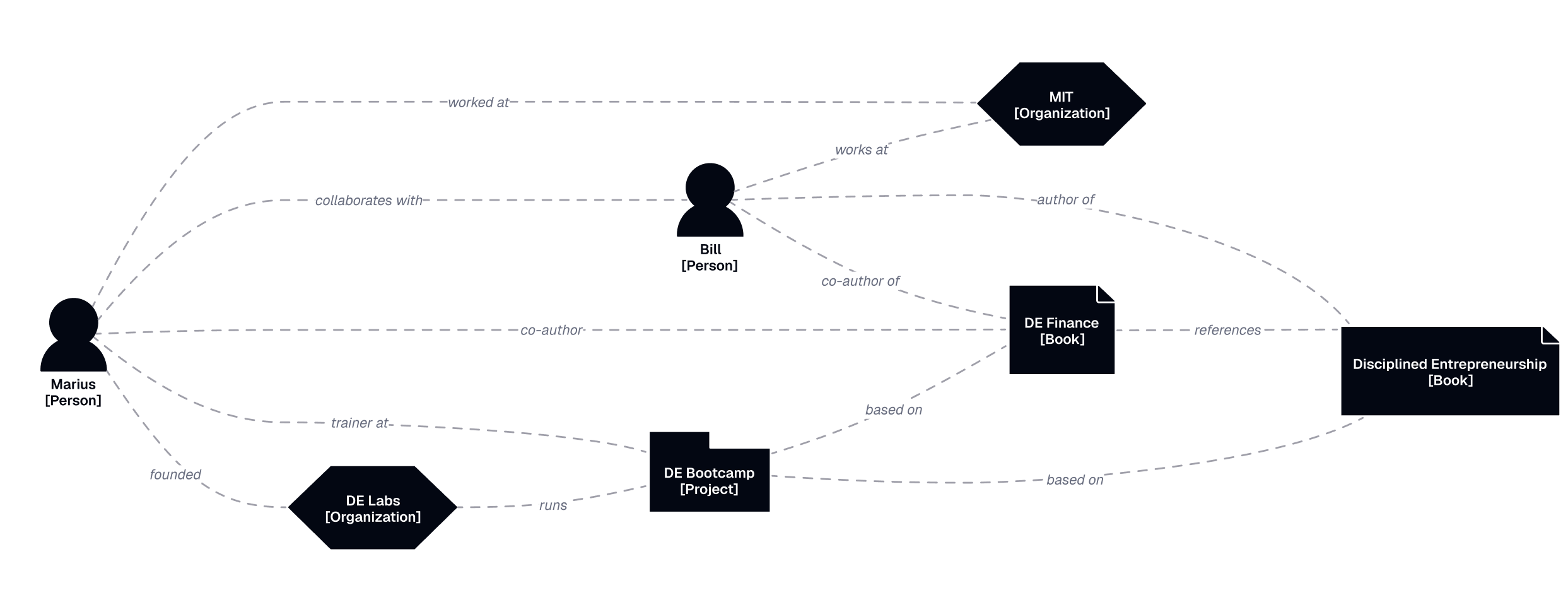
The core intelligence. This transforms raw data into structured memories across all three layers. In the GAM framework, this is the “Memorizer.” I think of it as the sleeping brain: it looks at all the raw data from the day, extracts what matters, and consolidates it into memory.
The pipeline has six stages:
Filter raw data. Figure out what’s user-relevant and what’s noise. An agent’s internal reasoning trace is not my memory. My request to the agent is. This is a critical step, and I haven’t fully solved it. The filtering rules live in the
memory-managementcapabilities.Extract episodes. The easiest part. Turn raw sessions into structured atomic events in Markdown.
Extract semantic information. The hard part. Check if entities and relationships already exist before creating new ones (to avoid duplicates), figure out which facts go on which nodes, and handle contradictions with existing data. Graph integrity depends on this.
Extract procedural information. The hardest part. Procedural knowledge is often implicit and unstructured. It requires pattern recognition across multiple events and usually user confirmation before adding to procedural memory. I haven’t solved this yet. Most of my procedural memory is still manually curated.
Update summaries and views. Rebuild temporal summaries and regenerate any domain views whose trigger conditions are met.
Expiration checks. Check for expired items and apply the relevant policies: archive, deprecate, or delete. I haven’t implemented this yet either.
Processing runs primarily as “sleep-time compute,” during low-activity periods overnight. This mirrors biological sleep consolidation, where the hippocampus replays and organizes the day’s experiences. It can also run on demand.
3. Retrieval
Assembles an active context for a specific task by pulling from all three layers, plus views and summaries.
In theory, retrieval combines:
Graph traversal to follow relationships and discover connected context
Vector search across events and temporal summaries
View lookup to pull pre-assembled domain perspectives
Priority weighting to boost identity-level nodes and current priorities
Temporal weighting so recent memories rank higher by default
Procedural matching to find relevant capabilities and workflows for the task at hand
The output is the active context: a structured package of everything the agent needs for this specific task, and nothing extra (this is important to avoid context rot).
Retrieval is the hardest problem. Active context is the small thing that everything else was built to produce. How do I retrieve exactly what I need for this specific task? How do I make sure the context is relevant, not overwhelming, and not stale? I don’t have a good answer yet. But the architecture gives me the right building blocks to iterate on.
4. Evolve
A meta-mechanism that improves the memory system itself over time. Unlike Process (which operates on data), Evolve operates on structure, procedures, and quality:
Schema evolution: new entity types, relationship types, or procedural categories as my life changes.
Decay and deprecation: temporal decay for stale facts, archiving low-access events, and deprecating old preferences. Configurable per entity type and domain.
Conflict resolution: detecting contradictions between memories and applying resolution policies. Some are automatic (newer wins), some require my confirmation.
Quality assessment: evaluating completeness and consistency. Flagging gaps. “No events about project X in three months. Is it still active?”
Feedback integration: my explicit corrections, preference updates, and structural changes.
Forgetting: intentional removal of outdated or noisy memories. Not passive decay but active curation.
This is still theoretical. As of today, evolution equals manual work on my end.
What’s Next
This architecture is v0.1.0 alpha. It’s imperfect, incomplete, but most importantly, it starts to be useful. The three-layer model (semantic, procedural, episodic) has already improved my OpenClaw conversations. Much of the curation is still manual.
The biggest unsolved problems that I plan to tackle next:
Capture more raw data to turn into episodic or semantic memory: Apple Health data, geolocation, voice memos, workout data, blood tests or medical records, meeting notes, etc.
I plan to build a skill per day (and end the year with 350+ useful skills).
Move everything to one place (I am thinking about SurrealDB, which supports knowledge graphs, vector embeddings, and SQL queries).
Build MCPs and webhooks to make it accessible to all my tools (currently, only OpenClaw has access, and I manually install skills in Claude).
Build skills, plugins, and prompts for Claude Code, Perplexity, OpenClaw, and other tools to properly retrieve and capture data from the memory layer.
If you’re building something similar, or if you see gaps I’m missing, I’d like to hear about it. This is an open problem, and I don’t think anyone has cracked it yet.
The Research Behind This
Before building, I researched other systems and read through recent arXiv papers on memory mechanisms in LLM-based agents from 2023 to 2026. The research is solid, and many taxonomies are well-established. But nobody has built a unified personal memory layer that works across multiple AI tools and belongs to the user. The pieces exist but the integration doesn’t. This architecture is my synthesis, informed by the literature but shaped by months of building and breaking personal memory systems.
Human memory science: Tulving’s episodic and semantic memory taxonomy is the foundation. For the biological basis of sleep-time consolidation, see this neural network account of memory replay.
AI agent architectures: Mem0 / GAM is the closest existing system to what I’m describing, with a 26% accuracy improvement over OpenAI’s memory. MemGPT/Letta introduced the hierarchical memory tiers. AriGraph validated using a unified knowledge graph. The best single reference for the field is A Survey on Memory Mechanisms in the Era of LLMs. Sleep-time compute is the technical basis for offline consolidation.
Portability and governance: The Memory Interchange Format is the first open standard for portable memory. Stanford’s Human Context Protocol proposes the governance model. For strategic context, see SynLabs on the battle for personal context and DTI on AI data portability.
Forgetting and quality: Human-like remembering and forgetting in LLM agents informed the decay approach. Research on effective context windows proves that nominal context size is not effective context size.
There's A LOT to unpack here, but super interesting and without a doubt the #1 challenge I've been thinking about lately with regards to using multiple AI tools/platforms/agents. I'll have another read and will ping you with questions...Good stuff!
"Fun/Play - completely absent. Zero representation in your vault. No folder, no file, no tag. This is a structural gap, not a lifestyle choice. Play is where creative recombination happens. Its absence in the architecture means it's either invisible to your system (happening but untracked) or actually missing from your life. Either way, the system can't learn from it."
I should thank you especially for this one :))