

Augmented Organizational Memory
How AI will probably solve your organizational knowledge problem, which is either lost when employees leave, buried where nobody remembers, or last updated in 2006.


New employee. First day.
If your organization is functional, IT would have them set up by lunch with a shiny new email account and access to Slack, Google Drive, Confluence, the CRM, or whatever. They get access to onboarding documentation and are assigned a senior guide or mentor.
This is how it should work, at least in theory. But reality bites. The mentor is too busy to spend time explaining the basics (even if they do, they suffer from a terrible case of the Curse of Knowledge, i.e., they can’t unlearn how the organization works and step into the new employee’s shoes or mind). The employee’s confused face tells it all: they understand almost nothing, they don’t know who is who, or how decisions get made here, or where to find real information versus the outdated onboarding docs, or what happened last quarter, or why the team stopped using that vendor, or who actually owns the pricing model, or anything else. It will take them eight months to a year to reach full productivity, longer for leadership roles. Not because they’re slow, but because the knowledge they need has no structure they can navigate.
Now, imagine replacing an employee with an AI agent, and you can see why it will fail in a similar way. They can access your documents in Drive, Dropbox, Notion, or Confluence, but they can’t understand the organizational context that makes those documents useful. The knowledge is scattered across tools, implicit in people’s behavior, contradictory between sources, and frequently stale. Feeding raw documents into an agent doesn’t solve this; it gives the agent the same disorienting experience as the new hire.
How do we fix this?
How Organizations Forget
I saw this in many companies, regardless of size. Critical organizational knowledge lives only in people’s heads (for example, that senior mentor from above is the only person who remembers why the pricing model changed, how that client prefers to receive estimates or purchase orders, or which approaches were already tried and abandoned)
When an employee leaves, the real loss is not the cost of recruiting a replacement. It’s the procedural and tacit knowledge that was never written down, and the cost of repeating mistakes that were never documented.
Sometimes they are properly documented, but nobody has any idea they exist or where they are saved (because, let’s be honest, in many organizations, everyone saves files and information anywhere but where they should be). Precious knowledge is buried in documents nobody can find in Confluence, Slack, and Google Docs.
Let’s say they are documented and available in Confluence, where everyone can find them. But those onboarding guides and procedures (SOPs) quickly go stale. The 90-9-1 rule applies: 90 percent of employees consume, 9 percent contribute occasionally, and 1 percent actually create. Without active maintenance, this information will become outdated.
Technology hasn’t solved this because the problem was never technological. RAG (retrieval-augmented generation) systems hallucinate because the source content is inconsistent and poorly curated, so fixing them doesn’t fix hallucination. Knowledge graphs fracture when the same information gets stored in four different ways.
AI doesn’t make these problems worse, but it makes them more visible and more costly. Every agent interaction now exposes gaps that humans learned to work around through relationships and hallway conversations. The gaps were always there; now they have consequences that cost.
Three Layers of Organizational Memory
In my previous article on personal AI memory, I described a three-layer architecture I use to build my personal memory: semantic, procedural, and episodic. The same model scales to organizations, with different instruments and different challenges at each layer.
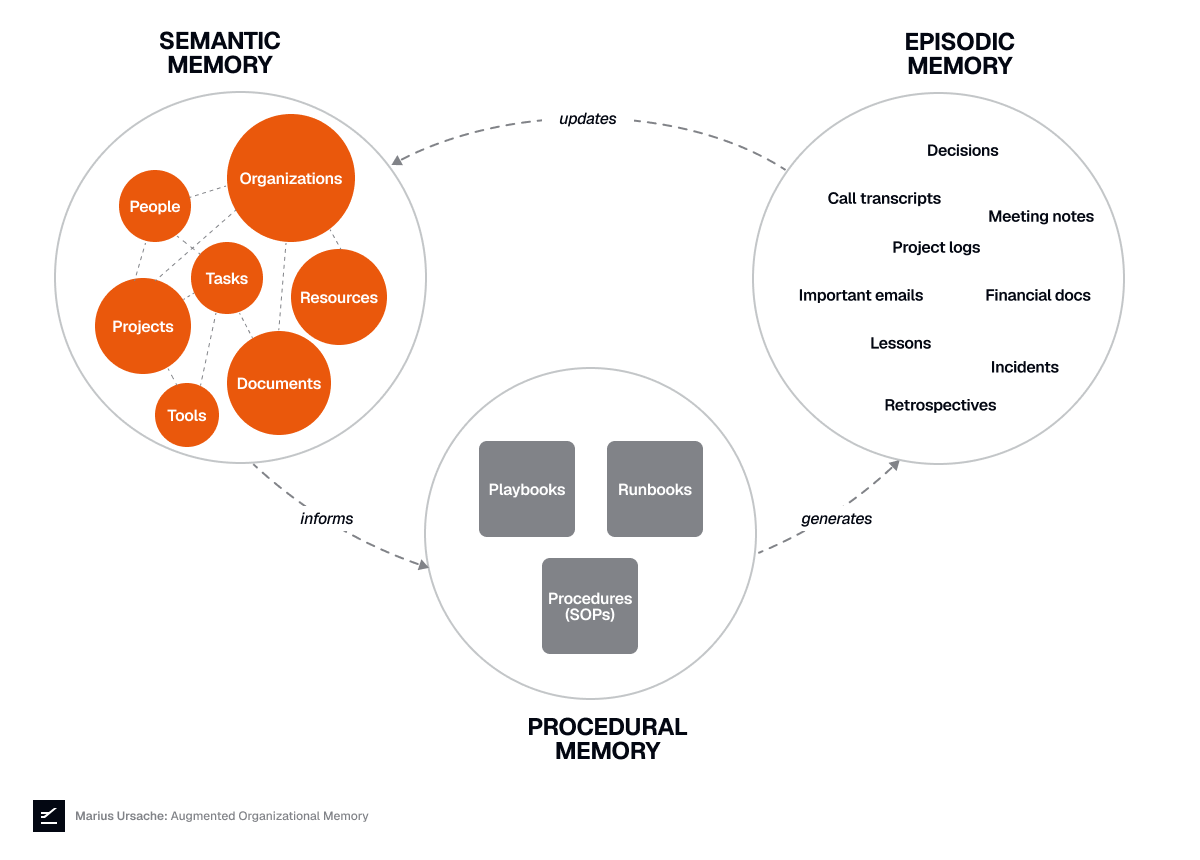
Semantic Memory: What the Organization Knows
Semantic memory is a complex map of people (employees, leads, clients), organizations (self, clients, suppliers, competitors), projects (or products), tasks, concepts, resources, and tools; all the relationships among them; and many facts, beliefs, and preferences associated with various entities and relationships.
Without a shared semantic foundation, every person and every AI agent builds their own incomplete mental model. Put ten people in a room, and you’ll get ten different understandings of “what we know about client X.” Knowledge is only useful when it’s connected: the product roadmap matters because of the client relationship, which matters because of the competitive position. Isolated facts don’t become organizational knowledge until they’re linked.
Because the organizational knowledge lives in multiple systems (files, CRMs, people’s heads), there is no single map. For AI agents, semantic memory is the foundation, and without it, they default to generic knowledge instead of your organization’s specific context.
Procedural Memory: How the Organization Does Things
Procedural memory is captured through three instruments that form a hierarchy:
SOPs (standard operating procedures) for routine, recurring tasks
Runbooks for defined operational processes with predictable steps
Playbooks for dynamic scenarios requiring judgment and cross-functional coordination
In high-performing organizations, these nest: playbooks reference runbooks, which embed SOPs, creating layered procedural knowledge. This is the most neglected layer, and the one that matters most. When people leave, it’s not the facts that walk out the door. It’s the “how we actually do it here,” the way decisions get made, the unwritten rules, the judgment calls that live in no document. Most organizations treat procedures as static documents written once and never updated, describing how things were done in 2023, not how they are done now.
For AI agents, procedural memory is the difference between an agent that can look things up and one that can do work the way your organization does it. System prompts define agent behavior more than model capabilities, and procedural memory should feed those prompts. Recently, Claude has established its skills model as an industry standard, but even these skills quickly become stale because an organization’s way of doing things evolves with lessons learned.
Episodic Memory: What Has Happened
Episodic memory includes project history, incident postmortems, decision logs, client call transcripts, and other time-bound events. The most systematized instrument here is the postmortem. Google and Datadog have defined the best practices, and modern tools generate AI-assisted postmortems from Slack conversations and monitoring data.
But the least systematized is the most important: recording decisions made along the way (and the reasoning behind them). Without decision records, teams repeat mistakes, ignore existing processes (because they don’t understand the reasoning behind them), and lose the “why” behind current practices. “Why did we stop using vendor X?” has an answer, but it’s in someone’s head, not in a record anyone can retrieve. For AI agents, episodic memory provides precedent: “Last time we tried this approach, here’s what happened.”
How Memory Should Be Kept Alive
The technology for storing knowledge is largely solved; keeping it alive is the unsolved problem.
Capture: Gets knowledge out of heads and into a digital repository by writing or inferring SOPs, processing documentation, transcribing onboarding calls, client interviews, etc.
Consolidation: Processes captured data and adds relevant information to the relevant layer (semantic entities, relationships, and facts). Keeps stored knowledge accurate and current. Discards stale knowledge.
Retrieval: Makes the right knowledge findable at the right time (using a hybrid search: knowledge graph retrieval, RAG with precise metadata, combined with file or database search). Accessible to both AI agents and humans.
Evolution: Adapts the system as the organization changes, by changing the system, not the information inside (a self-healing, self-evolving system aligned with organizational performance).
Back to the First Day
Imagine if the new employee on day one had the map: who knows what, how things actually get done, what was tried before, and why it failed. Imagine if your AI agents had that same context, not just access to documents, but the structure that makes them useful.
I don’t know of any tool that does this for an entire organization. But building something more focused is not impossible. If you want to try, start with onboarding. It’s the fastest, most impactful place to test this, and the results compound from there.
Let me know if you need help.
tor is too busy to spend time explaining the basics (even if they do, they suffer from a terrible case of the Curse of Knowledge, i.e., they can’t unlearn how the organization works and step into the new employee’s shoes or mind). The employee’s confused face tells it all: they understand almost nothing, they don’t know who is who, or how decisions get made here, or where to find real information versus the outdated onboarding docs, or what happened last quarter, or why the team stopped using that vendor, or who actually owns the pricing model, or anything else. It will take them eight months to a year to reach full productivity, longer for leadership roles. Not because they’re slow, but because the knowledge they need has no structure they can navigate.
Now, imagine replacing an employee with an AI agent, and you can see why it will fail in a similar way. They can access your documents in Drive, Dropbox, Notion, or Confluence, but they can’t understand the organizational context that makes those documents useful. The knowledge is scattered across tools, implicit in people’s behavior, contradictory between sources, and frequently stale. Feeding raw documents into an agent doesn’t solve this; it gives the agent the same disorienting experience as the new hire.
How do we fix this?
How Organizations Forget
I saw this in many companies, regardless of size. Critical organizational knowledge lives only in people’s heads (for example, that senior mentor from above is the only person who remembers why the pricing model changed, how that client prefers to receive estimates or purchase orders, or which approaches were already tried and abandoned)
When an employee leaves, the real loss is not the cost of recruiting a replacement. It’s the procedural and tacit knowledge that was never written down, and the cost of repeating mistakes that were never documented.
Sometimes they are properly documented, but nobody has any idea they exist or where they are saved (because, let’s be honest, in many organizations, everyone saves files and information anywhere but where they should be). Precious knowledge is buried in documents nobody can find in Confluence, Slack, and Google Docs.
Let’s say they are documented and available in Confluence, where everyone can find them. But those onboarding guides and procedures (SOPs) quickly go stale. The 90-9-1 rule applies: 90 percent of employees consume, 9 percent contribute occasionally, and 1 percent actually create. Without active maintenance, this information will become outdated.
Technology hasn’t solved this because the problem was never technological. RAG (retrieval-augmented generation) systems hallucinate because the source content is inconsistent and poorly curated, so fixing them doesn’t fix hallucination. Knowledge graphs fracture when the same information gets stored in four different ways.
AI doesn’t make these problems worse, but it makes them more visible and more costly. Every agent interaction now exposes gaps that humans learned to work around through relationships and hallway conversations. The gaps were always there; now they have consequences that cost.
Three Layers of Organizational Memory
In my previous article on personal AI memory, I described a three-layer architecture I use to build my personal memory: semantic, procedural, and episodic. The same model scales to organizations, with different instruments and different challenges at each layer.
Semantic Memory: What the Organization Knows
Semantic memory is a complex map of people (employees, leads, clients), organizations (self, clients, suppliers, competitors), projects (or products), tasks, concepts, resources, and tools; all the relationships among them; and many facts, beliefs, and preferences associated with various entities and relationships.
Without a shared semantic foundation, every person and every AI agent builds their own incomplete mental model. Put ten people in a room, and you’ll get ten different understandings of “what we know about client X.” Knowledge is only useful when it’s connected: the product roadmap matters because of the client relationship, which matters because of the competitive position. Isolated facts don’t become organizational knowledge until they’re linked.
Because the organizational knowledge lives in multiple systems (files, CRMs, people’s heads), there is no single map. For AI agents, semantic memory is the foundation, and without it, they default to generic knowledge instead of your organization’s specific context.
Procedural Memory: How the Organization Does Things
Procedural memory is captured through three instruments that form a hierarchy:
SOPs (standard operating procedures) for routine, recurring tasks
Runbooks for defined operational processes with predictable steps
Playbooks for dynamic scenarios requiring judgment and cross-functional coordination
In high-performing organizations, these nest: playbooks reference runbooks, which embed SOPs, creating layered procedural knowledge. This is the most neglected layer, and the one that matters most. When people leave, it’s not the facts that walk out the door. It’s the “how we actually do it here,” the way decisions get made, the unwritten rules, the judgment calls that live in no document. Most organizations treat procedures as static documents written once and never updated, describing how things were done in 2023, not how they are done now.
For AI agents, procedural memory is the difference between an agent that can look things up and one that can do work the way your organization does it. System prompts define agent behavior more than model capabilities, and procedural memory should feed those prompts. Recently, Claude has established its skills model as an industry standard, but even these skills quickly become stale because an organization’s way of doing things evolves with lessons learned.
Episodic Memory: What Has Happened
Episodic memory includes project history, incident postmortems, decision logs, client call transcripts, and other time-bound events. The most systematized instrument here is the postmortem. Google and Datadog have defined the best practices, and modern tools generate AI-assisted postmortems from Slack conversations and monitoring data.
But the least systematized is the most important: recording decisions made along the way (and the reasoning behind them). Without decision records, teams repeat mistakes, ignore existing processes (because they don’t understand the reasoning behind them), and lose the “why” behind current practices. “Why did we stop using vendor X?” has an answer, but it’s in someone’s head, not in a record anyone can retrieve. For AI agents, episodic memory provides precedent: “Last time we tried this approach, here’s what happened.”
How Memory Should Be Kept Alive
The technology for storing knowledge is largely solved; keeping it alive is the unsolved problem.
Capture: Gets knowledge out of heads and into a digital repository by writing or inferring SOPs, processing documentation, transcribing onboarding calls, client interviews, etc.
Consolidation: Processes captured data and adds relevant information to the relevant layer (semantic entities, relationships, and facts). Keeps stored knowledge accurate and current. Discards stale knowledge.
Retrieval: Makes the right knowledge findable at the right time (using a hybrid search: knowledge graph retrieval, RAG with precise metadata, combined with file or database search). Accessible to both AI agents and humans.
Evolution: Adapts the system as the organization changes, by changing the system, not the information inside (a self-healing, self-evolving system aligned with organizational performance).
Back to the First Day
Imagine if the new employee on day one had the map: who knows what, how things actually get done, what was tried before, and why it failed. Imagine if your AI agents had that same context, not just access to documents, but the structure that makes them useful.
I don’t know of any tool that does this for an entire organization. But building something more focused is not impossible. If you want to try, start with onboarding. It’s the fastest, most impactful place to test this, and the results compound from there.
Let me know if you need help.